
D3の山下が,2026年2月26日(木)~3月1日(日)にイタリアのトレントで開催されたThe 16th International Workshop on Spoken Dialogue Systems Technology (IWSDS2026) で発表を行いました.IWSDSは,音声対話システムに関する国際ワークショップです.
発表について
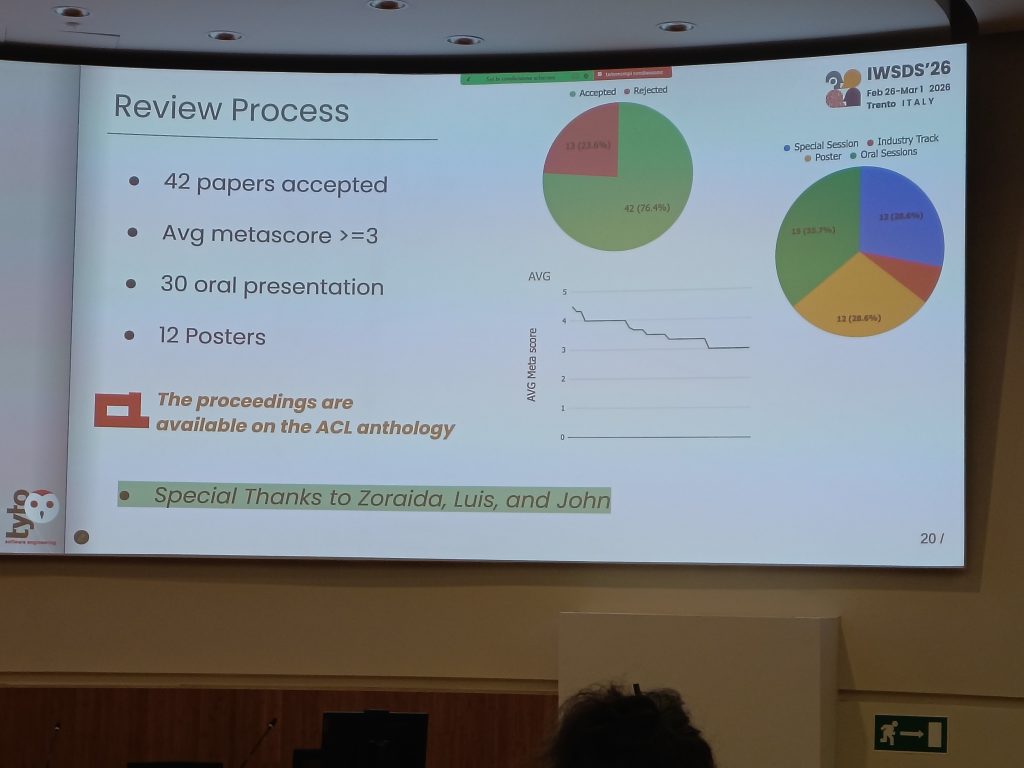
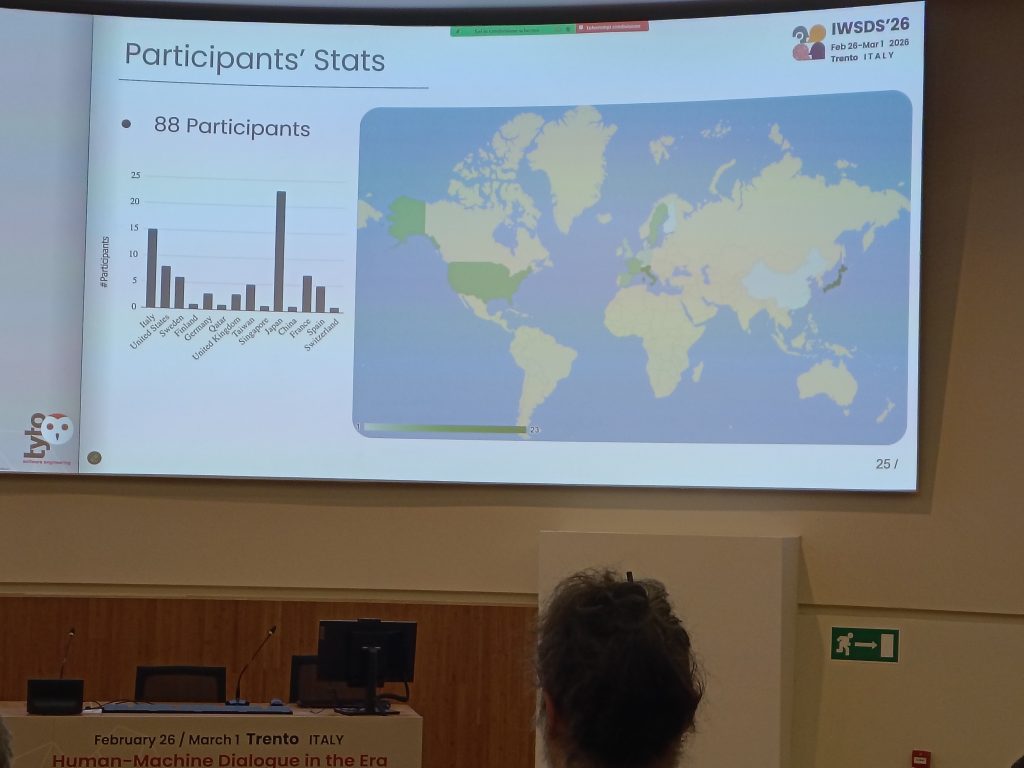
発表件数は,口頭発表が30件,ポスター発表が12件でした.55件の投稿があり,採択率は76.4%でした.参加者は88名で,日本から23人,イタリアから15人,その他,アメリカ,フランス,スウェーデン,スペイン,台湾,ドイツ,イギリス,フィンランド,カタール,シンガポール,中国,スイスといった様々な地域から研究者が集まりました.
今年は3件のKeynoteがありました.
- Toward Socially Intelligent Dialogue Systems: From Foundational Models to Mental Models (Asli Celikyilmaz, Meta Fundamentals AI Research)
社会的な知性を持つ対話システムに必要な能力として,Collaboration(協力する能力),Personalization(個人の好みに適応する能力),Mental State Reasoning(他者の考えや意図を推論する能力)の3つが紹介されました.また,現時点における課題として,人間とAIが協力して共同作業を行う際にはAIのコミュニケーションが冗長になりがちなこと,強化学習の枠組みにおいて人間の好みを報酬として表現することには限界があること,および,Theory of Mindを強化学習に組み込むための方法論が確立されていないことなどが挙げられました.発表者は,今後の展望としてEmbodiedな対話システムの構築を目指しており,その実現に向けては,ベンチマークが不足している点が課題となっていました. - Towards more Human-like Conversational Agents: Opportunities and Challenges (Gabriel Skantze, KTH Royal Institute of Technology)
人間同士のCoordination(協調)を対話システムとの対話においても実現するための要素として,特に音声の観点から,ターンテイキング,バックチャンネル,インクリメンタル発話生成といった要素が紹介されました.ターンテイキングについては,そのタイミングは教師あり学習によってモデル化することが可能であり,いつ話すかの予測には有効である一方で,何を話すべきかを決定することは難しいという課題が指摘されました.バックチャンネルについては,LLMにバックチャンネルを選択させる研究が紹介されました.インクリメンタル発話生成については,生成速度に応じて発話速度を動的に調整することで,人間らしい応答タイミングを実現する研究が紹介されました. - Towards Meaningful Control of Multimodal XR Experiences and the Role of Spoken Dialogue (Giulio Jacucci, University of Helsinki)
近年,Genieなどに代表されるWorld Model(世界モデル)が構築され,その環境内で人間と対話システムがインタラクションを行う研究が進められています.このような環境において自然なインタラクションを実現するために,Embodiedな対話システムの役割,性格,非言語スタイルなどを,ユーザに応じてLLMで動的にカスタマイズする研究が紹介されました.現状の課題として,対話システムが自然なインタラクションを行う上で,Timing(発話や動作のタイミング),Grounding(文脈や環境への接地),Adaptation(ユーザ適応)といった要素が十分に実現されていないことが挙げられました.
山下は,Human-centered Interactionのセッションで口頭発表を行いました.この研究では,オンラインでの見守り対話を行う保育者音声対話システムの構築に資する知見を得ることを目的として,子どもと保育者の対話を収集し,その対話を,ターンテイキング,バックチャンネル,および,発話意図の観点から分析しました.分析の結果,保育者音声対話システムにはターン制が適していることなどが明らかになりました.質疑応答では,ジェスチャや目線といった非言語情報がターンテイキングやバックチャンネルの発生に影響している可能性について,質問とコメントをいただきました.
Analysis of Child-Caregiver Interactions for Developing a Caregiver Spoken Dialogue System Proceedings Article
In: The 16th International Workshop on Spoken Dialogue Systems Technology, 2026.

受賞のあった論文
Best paperとOutstanding paperが1本ずつ選ばれました.
- Do Audio and Visual Tokenizers Capture Backchannels? (Benoit Favre, Auriane Boudin)
Best paperに選ばれた論文です.この研究では,音声や映像のトークナイザが,対話中のバックチャンネルをどの程度表現できるかを評価しました.具体的には,トークナイザの表現を基に,バックチャンネルとそれ以外を分類できるかを評価しました.結果として,映像トークナイザよりも音声トークナイザの方がバックチャンネルをよく捉えることができ,両方を組み合わせた場合に精度が向上しました. - The Context Trap: Why End-to-End Audio Language Models Fail Multi-turn Dialogues (Zhi Rui Tam, Wen-Yu Chang, Yun-Nung Chen)
Outstanding Paperに選ばれた論文です.この研究では,End-to-Endの音声言語モデルがマルチターンのタスク指向対話において十分な対話品質を維持できるかを検証しました.具体的には,LLMを用いて自然さや一貫性といった対話品質を評価しました.その結果,End-to-Endモデルは文脈保持やトピック追跡といった対話モデリング能力が不十分であり,対話が進むにつれて自然さや一貫性が大きく低下することが明らかになりました.
参加してみて
IWSDS2026は音声対話システムに関する会議ですが,音声だけでなくマルチモーダル情報を取り入れて発話を生成しようとする研究が多く見られました.また,小規模な会議であり,コーヒーブレイクの時間が頻繁に設けられていたため,参加者同士が気軽に話しかけやすく,交流しやすい雰囲気でした.
Excursionとして,会議の初日には,Buonconsiglio城のツアーがありました.Buonconsiglio城は13世紀ごろに建てられたものです.様々な時代に増築を繰り返したため,各階がそれぞれ異なる素材で作られており,窓の形も異なっています.壁や天井にはフレスコ画が描かれており,21世紀の現在になってもまだ鮮やかに残されていました.




来年度のIWSDSは,2027年2月〜5月にアメリカで開催される予定です.