
出島メッセ長崎で2025年3月10~14日に開催された言語処理学会第31回年次大会(NLP2025)にて,大橋(D2),周(D2),山下(D2),銭本(D1),飯塚(M2),望月(M2),津田(B4)の7名が参加しました.
今年の発表件数は777件(昨年:599)で,参加者数は2,248名(昨年:2,121)とどちらも過去最多でした.
自身の発表について
大橋は,リアルタイム音声対話モデル J-Moshi の構築に関する研究を発表しました.大規模な日本語音声データを用いたファインチューニングによって,英語の音声対話モデル Moshi の日本語化を実現しました.
日本語Full-duplex音声対話システムの試作 Proceedings Article
In: 言語処理学会 第31回年次大会 発表論文集, 2025, (言語処理学会第31回年次大会委員特別賞).

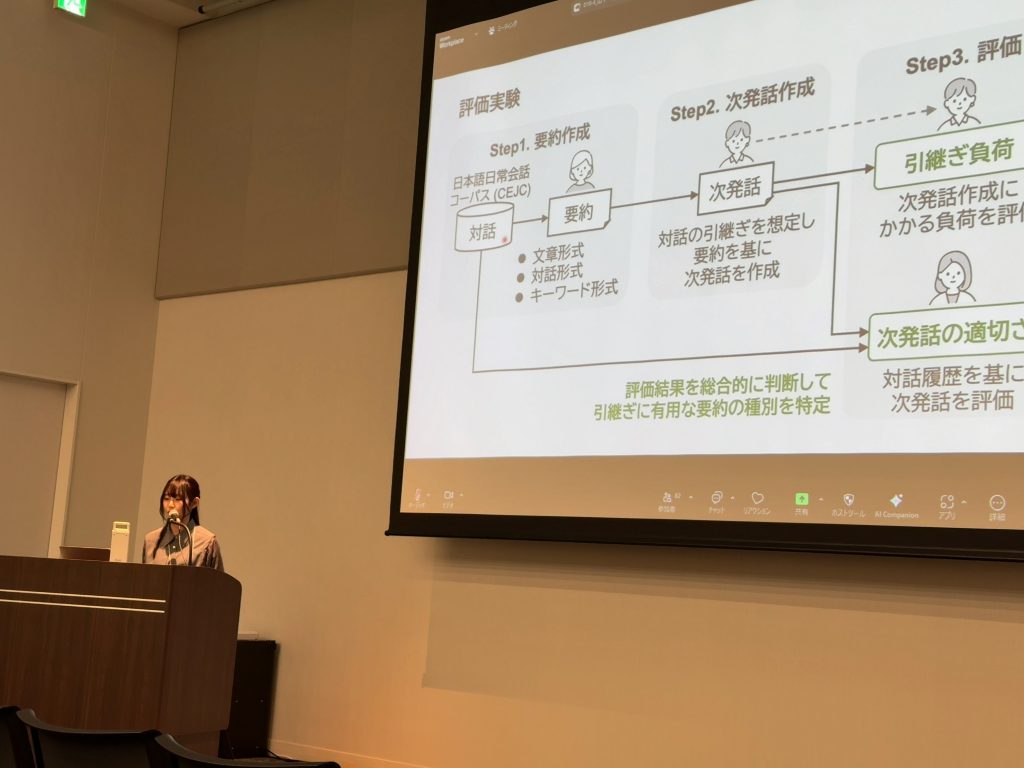
山下は,コールセンタで行われるような対話の引継ぎにおいて,対話要約の種別が引継ぎにどのような影響を及ぼすかを調査しました.文章形式・対話形式・キーワード形式の要約を比較した結果,対話形式の抽象型要約が,引継ぎの負荷や次発話の適切さの点で優れており,対話の引継ぎに有用であることが示唆されました.
対話要約の種別が対話の引継ぎに及ぼす影響の調査 Proceedings Article
In: 言語処理学会 第31回年次大会 発表論文集, pp. 3999–4004, 2025.
周は,キャッチコピー共同作成対話コーパスに対する第三者評価を収集し,自己評価などとの関係を分析した結果について発表しました.キャッチコピーの評価は評価者間の相関が低く,統一的な評価が難しいことがわかりました.
キャッチコピー共同作成対話コーパスにおける第三者評価と自己評価の関係分析 Proceedings Article
In: 言語処理学会 第31回年次大会 発表論文集, 2025.

銭本は,雑談の中でアンケートを実施できるアンケート対話システムについて発表しました.人間評価実験と実証実験を通して,アンケート対話システムが紙のアンケートと類似した回答を取得することができることを検証しました.
質問誘導に基づくアンケート対話システムの開発 Proceedings Article
In: 言語処理学会 第31回年次大会 発表論文集, 2025.

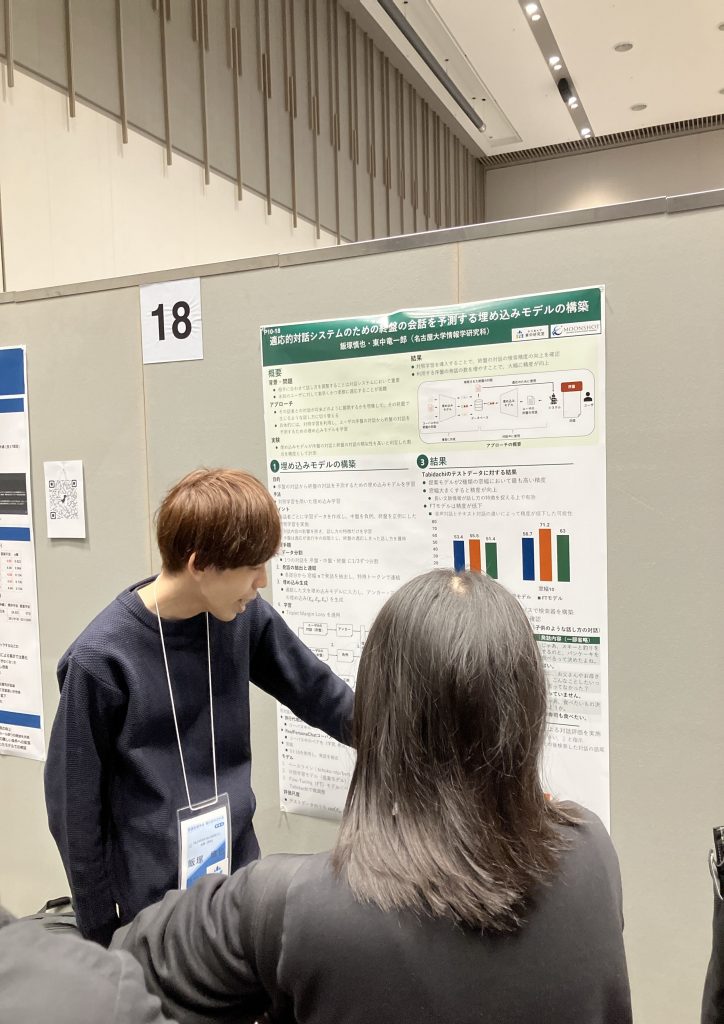
飯塚は,ユーザに適応して話す対話システムの実現に向けて,終盤の会話を予測する埋め込みモデルを構築し,その研究成果をポスター発表しました.本研究では,未知のユーザとの対話が将来どのように展開するかを予測し,その予測を用いて応答生成することで,ユーザに適応する手法を提案しています.
適応的対話システムのための終盤の会話を予測する埋め込みモデルの構築 Proceedings Article
In: 言語処理学会 第31回年次大会 発表論文集, 2025.

望月は,複数人同時対話の枠組みにおいて,人と対話ロボットのインタラクション中に生じた問題(異常)を自動で検出することを目的としたデータセット作成,モデル構築,およびフィールド実験について発表しました.フィールド実験の結果から,動画と音声を入力とするマルチモーダル異常検出モデルの出力に基づいてアラートを提示することが,オペレータの介入の補助に有用であることを実証しました.
実インタラクション映像から構築したマルチモーダルモデルを用いた人とロボットのインタラクションにおける異常検出 Proceedings Article
In: 言語処理学会 第31回年次大会 発表論文集, 2025.

津田は,話者間の関係性に着目したマルチパーティ雑談対話コーパスの構築について発表しました.構築したコーパスを用いた分析を通じて,話者間の関係性が対話後アンケートの結果に与える影響や,対話における関係性の表出度合いについて調査しました.
Multi-Relational Multi-Party Chat Corpus: 話者間の関係性に着目したマルチパーティ雑談対話コーパス Proceedings Article
In: 言語処理学会 第31回年次大会 発表論文集, 2025.

チュートリアル
合計で4名の方からのチュートリアルがありました:
- Benjamin Heinzerling 先生(理化学研究所/東北大学)・横井 祥 先生(国立国語研究所/東北大学/理化学研究所)・小林 悟郎 先生(東北大学/理化学研究所)
言語モデルの内部機序:解析と解釈
言語モデルの内部機序の分析や解釈の方法について,背景となる考え方から具体的な手法を解説する講演でした.そもそも我々は言語モデルにどのような表現を持ってほしいのか,という話から,言語モデルの内部の計算過程や出力結果の分析がわかりやすく詳細に説明されました. - 松村 結衣 先生(株式会社Helpfeel/UN Smart Maps Group)
地理情報と言語処理 実践入門
ハンズオン形式で,言語処理技術を活用した地理情報の可視化や解析の事例を紹介する講演でした.生成AIを用いた地理情報検索などの様々なテクニックも紹介され,今後より日常生活が便利になる未来を展望できました. - 谷中 瞳 先生(東京大学/理化学研究所)
ことばの意味を計算するしくみ
我々が日ごろから使用していることば(自然言語)の意味の計算について,自然言語処理と計算言語学の2つのアプローチから様々な事例を紹介する講演でした.人がどのように言葉の計算をしているのかはまだ十分に解明されていませんが,様々な立場から検討し,反証することで言葉の意味についての真理に近づけるのではという可能性が示唆されました. - 鈴木 貴之 先生(東京大学)
人工知能の哲学入門
古典的人工知能の基本的な発想とその限界,現在の人工知能技術の特徴と進展,そして現代の人工知能に関する哲学的問いについて概観する講演でした.深層ニューラルネットワークや大規模言語モデルに関する哲学的問いが多く取り上げられ,⼈⼯知能研究が⾶躍的に発展した現在,知能や意味理解の本質を改めて問う内容となりました.
招待講演
合計で2名の方からの特別招待講演がありました:
- 坂井 美日 先生(鹿児島大学)
生成AIを活用した九州・琉球の言語継承支援に資する方言対話システムの開発 ―現状と課題
方言の継承支援に役立てることを目的として開発された,生成AIを活用した九州・琉球の方言対話システムについて紹介されました.試行錯誤の結果,Boasの3点セット(言語の規則を説明した文法,語彙の意味を説明した辞書,実際の用例集)をプロンプトに与えたり,ファインチューニングに用いたりすることで,実用的な方言対話システムを構築できたとのことです.ゼロショットのChatGPTでは文法的・意味的に許容できない非文が多かったのですが,3点セットを与えることで非文をなくすことができたと報告されており,他の低資源言語・方言の生成にも期待が持てる内容でした.また,方言を若い世代に継承するため,AIせごどん(西郷隆盛のアバタを持つAI方言対話システム)を構築し,実際に使ってもらう取り組みも始まっているそうです. - 堀川 友慈 先生(NTTコミュニケーション科学基礎研究所)
脳からの意味情報解読で探る視覚と言語の境界線
人間が特定の画像を見たときの脳活動パターンと,同じ画像を基盤モデルに入力した際のモデルの内部表現に一致が見られることから,大規模言語モデルを用いて人間の脳活動を解読できるとして,大規模言語モデルと脳情報デコーディングを融合した種々の研究について紹介されました.そもそも,人工的に構築した言語モデルを用いて,人間の複雑な脳活動から関連したテキストを出力できるという事実に驚き,この技術を応用することで,自身が見ているものに対してうまく言語化できていない人の脳活動や,言語が未発達の子どもの脳活動からも,見ている対象に対する言語的な解釈を得られるかもしれないという話が大変興味深かったです.
気になった発表
- 三田 雅人 (東大/サイバーエージェント), 吉田 遼, 深津 聡世, 大関 洋平 (東大)
作業記憶の発達的特性が言語獲得の臨界期を形成する(最優秀賞)
人間の言語獲得における臨界期仮説を,LLM の学習に取り入れることで学習効率の改善を目指した研究です.具体的には,幼児期の認知的な制約がむしろ言語学習に有利であるという知見に基づき,Transformer の注意機構に対して学習ステップに応じた制約を導入することで,ベースラインを超える性能を達成しました. - 趙 羽風, 加藤 万理子, 坂井 吉弘 (JAIST), 井之上 直也 (JAIST/理研)
大規模言語モデルにおける In-context Learning の推論回路(委員特別賞)
In-context Learning (ICL) の内部的なメカニズムの解釈を目指した研究です.ICL における推論回路として,LLM が3ステップの操作を行っているという仮説を立て,実験によって各ステップの存在を説明した点や,実際にその3ステップが性能に寄与することを示した点が面白いと感じました. - 叶 高朋, 小川 厚徳, デルクロア マーク (NTT), チェン ウィリアム (CMU), 福田 りょう, 松浦 孝平, 芦原 孝典 (NTT), 渡部 晋治 (CMU)
ReShape Attention による音声と言語の基盤モデルの統合(委員特別賞)
音声基盤モデルと言語基盤モデルを,学習可能なパラメータを追加することなく統合する研究です.提案された ReShape Attention は,次元数が異なる埋め込みを時間方向に分割することで,写像を追加することなく音声と言語の cross-attention を実現しており,有用性の高い手法だと思いました. - 大中 緋慧 (NAIST/理研), 河野 誠也 (理研/NAIST), 大西 一誉 (NAIST/理研), 吉野 幸一郎 (NAIST/理研/科学大)
リアルタイム音声対話システムのための応答タイミングと短文応答の同時予測(委員特別賞)
音声対話システムの応答遅延を緩和するための短文応答を予測する研究です.いつターンを取るかを予測するだけでなく,その対話文脈に応じた適切な短文応答音声の選択を,対照学習によって学習しています. - 矢野 一樹 (東北大), 伊藤 拓海 (東北大/Langsmith), 鈴木 潤 (東北大/理研/NII)
モデル拡張によるパラメータ効率的な LLM の事前学習(委員特別賞)
LLM の事前学習において,モデルの層を段階的に追加することで,学習におけるGPUメモリ要求量を削減する研究です.各学習段階における最適な層数は整数計画問題として定式化され,最大で50%以上のメモリ要求量を削減しながら,性能も維持できることが示されており,有用な手法だと感じました. - 篠田 一聡 (NTT人間情報研究所), 北条 伸克, 西田 京介, 水野 沙希, 鈴木 啓太, 増村 亮, 杉山 弘晃, 斎藤 邦子 (NTT人間情報研究所)
ToMATO:心の理論ベンチマークのためのロールプレイング LLMの心的状態の言語化
心の理論(Theory of Mind)を包括的かつ実応用に近い設定で評価可能なベンチマークであるToMATOを提案し,現状のLLMの心の理論を評価した研究です.誤信念をはじめとする 5 種類の心的状態(信念・意図・願望・感情・知識)を網羅的に評価できる点や,Big5性格特性を導入して,より実用的な文脈でモデルの心の理論を検証している点が興味深いと感じました.
おわりに
今年のNLPも発表件数,参加者数ともに過去最多が更新され,NLP分野の盛り上がりを実感しました.興味深い発表が非常に多く,それらの聴講を通して研究へのモチベーションが大いに高まりました.また,我々の研究に対して多くの質問,活発な議論があり,今後の研究の参考になりました.
NLP では発表以外にも様々な懇親会が開催され,どの懇親会も大盛況でした.同世代の研究者や企業の方とも交流する機会があり,大変充実した体験となりました.来年宇都宮で開催される年次大会にもぜひ参加したいと思います.



